Wan-Hua Her und Thomas Schmidt
Abstract
Mithilfe von computergestützten Ansätzen lassen sich heutzutage moderne kulturelle Artefakte in vielfacher Hinsicht analysieren. Dies ermöglicht insbesondere Digital Humanities Forscher*innen, die durch Verfahren wie beispielsweise Text Mining und Textanalyse neue Daten akquirieren, neue Erkenntnisse zu gewinnen und diese somit mit neuen Perspektiven hermeneutisch zu interpretieren.
Dieser Beitrag ist Teil einer Reihe von Beiträgen, die Forschungsprojekte aus den Jahren 2018-2020 im Bereich Digital Humanities vorgestellt. Im Folgenden werden vor allem aktuelle Forschungen im Zusammenhang mit modernen kulturellen Artefakten präsentiert: Fanfictions, deutschsprachige Songtexte und Gerichtsurteile.
Die drei Forschungsbeiträge sind:
- Investigating the Transformation of Original Work by the Online Fan Fiction Community: A Case Study for the TV show ‘Supernatural‘
- Der Einsatz von Distant Reading auf einem Korpus deutschsprachiger Songtexte
- Stilometrie in der Rechtslinguistik
Fanfictions
Der erste Beitrag wurde auf der Tagung „Digital Practices. Reading. Writing and Evaluation on the Web“ von Thomas Schmidt (Mitarbeiter am Lehrstuhl für Medieninformatik an der UR) und Nina Kleindienst (Studierende der Medieninformatik an der UR) vorgestellt.
In der Präsentation „Investigating the Transformation of Original Work by the Online Fan Fiction Community: A Case Study for the TV show ‘Supernatural‘“ vergleichen Schmidt und Kleindienst (2020) die Skripte der amerikanischen Fernsehserie Supernatural und die von deren Fans erstellte Fortsetzung, um linguistische Merkmale und Unterschiede bezüglich des Auftretens von Charakteren zu untersuchen. Das Paper findet man auf Research Gate.

Quelle: https://commons.wikimedia.org/wiki/File:Supernatural_title_card.jpg
Die Fan-Gemeinschaft von Supernatural ist sehr aktiv und gilt nach Marvel und Harry Potter als das drittbeliebteste Fandom auf Archive of our own. Das erste Korpus umfasst 307 TV-Skripts und insgesamt 2 Millionen Tokens, wobei das zweite Korpus 7,853 Fanfictions und 265 Millionen Tokens hat. Trotz des großen Unterschieds an der Menge der Tokens, liegt die durchschnittliche lexikalische Vielfalt des ersten Korpuses bei 0,19 und des zweiten Korpuses bei 0,1.


Die Analyse des Auftretens der Charaktere weist ebenfalls interessante Ergebnisse auf – in der Fernsehserie erscheinen die Protagonisten Sam und Dean in 100% und 99,7% aller Folgen, aber nur zu 70,8% und 89,9% in den Fanfictions. Andererseits erscheint Castiel in 76% der Fan-Geschichten, aber nur zu 46,6% in den Serienfolgen.

Insgesamt kann also eine Überrepräsentation von Nebencharakteren und eine Unterrepräsentation von Hauptfiguren festgestellt werden. Die Fallstudie von Supernatural zeigt nicht nur, wie und inwieweit Fan-Gemeinschaften das Quellmaterial umwandeln, sondern auch mögliche spannende Themen für weitere Forschungen.
Songtexte
Der nächste Beitrag, „Der Einsatz von Distant Reading auf einem Korpus deutschsprachiger Songtexte“, wurde auf der DHd 2020 (Digital Humanities im deutschsprachigen Raum) als Poster vorgestellt und stammt von Mitarbeitern und Studierenden am Lehrstuhl für Medieninformatik: Thomas Schmidt (Mitarbeiter), Marlene Bauer (Studierende), Florian Habler (Studierende), Hannes Heuberger (Studierende), Florian Pilsl (Studierende) und Christian Wolff (Professor). Das Poster erhielt den 3. Platz beim alljährlichen Poster-Slam der Dhd.

Lizenz zum Bild: Josua Köhler/Universität Paderborn, CC BY 3.0 DE
Markus Freudinger/Universität Paderborn, CC BY 3.0 DE

Lizenz zum Bild: Josua Köhler/Universität Paderborn, CC BY 3.0 DE
Markus Freudinger/Universität Paderborn, CC BY 3.0 DE
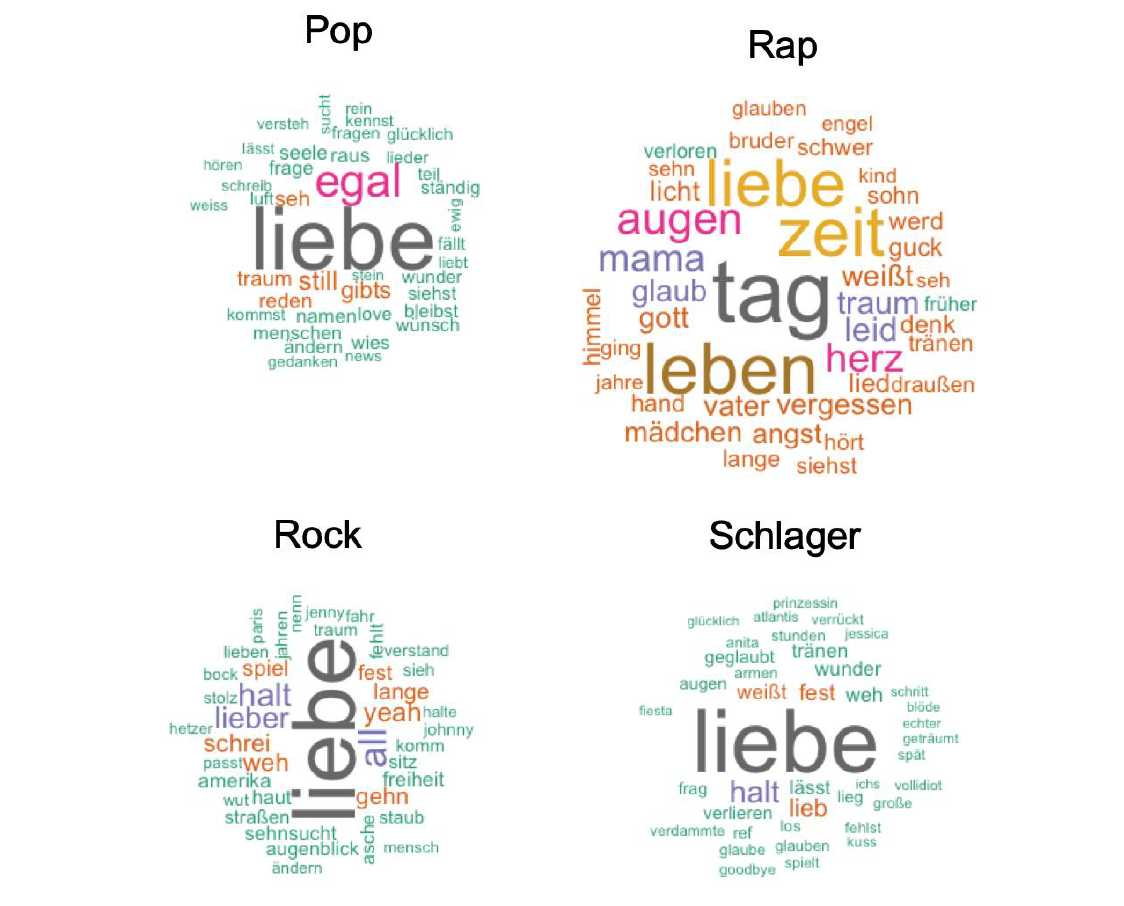
Schmidt et al. (2020) explorieren genrespezifische Unterschiede in deutschsprachigen Songtexten (Pop, Rock, Schlager und Rap) mittels Distant-Reading-Ansätzen wie beispielsweise Wortfrequenzanalyse, Sentimentanalyse und Topic Modeling. Zu diesem Zweck wurde ein Korpus bestehend aus 4.636 Songtexten von den bekanntesten Genrevertretern aus den 60er Jahren bis 2010 über LyrikWiki akquiriert.


Bei den ersten Ergebnissen der Wortfrequenzanalyse erkennt man, dass drei von zehn der am häufigsten vorkommenden Wörter „Welt“, „Leben“ und „Zeit“ in allen vier Genres gleichmäßig stark verteilt sind.


Bei der Sentimentanalyse weisen alle Genres auf eine insgesamt negative Polarität hin, wobei das Wort „Liebe“ und seine Varianten einen erheblichen Beitrag zur Positivität leisten. Auffällig ist dabei auch, dass die Genres Rap und Rock entgegen der Intuition im Vergleich zu anderen am Positivsten bewertet wurden.

Gerichtsurteile
Das letzte Paper, „Stilometrie in der Rechtslinguistik“, wurde auf der Tagung IRIS 2019 (Internationales Rechtsinformatik Symposioum) von Studierenden und Mitarbeitern am Lehrstuhl für Medieninformatik vorgestellt: Anna-Maria Auer (Studierende), Pascale Berteloot (Studierende), Bettina Mielke (Studierende), Christine Schikora (Studierende), Thomas Schmidt (Mitarbeiter) und Christian Wolff (Professor).
Auer et al. (2019) nutzen korpuslinguistische Analyseverfahren auf einer Sammlung von deutschsprachigen Gerichtsurteilen, um die Charakterisierung der Urteilssprache zu erforschen. Das Korpus ist von 90 Urteilen im klassischen Bereich des EU-Rechts wie z.B. Freizügigkeit aus dem Jahr 2018 aufgebaut.
Hinsichtlich der Stilometrie wird zuerst untersucht, ob es Unterschiede zwischen den österreichischen und deutschen Urteilssprachen gibt. Zur Durchführung der Stilometrie wurde das stylo-package für R verwendet. Die Ergebnisse der Clusteranalyse stellen mit wenigen Ausnahmen eine eindeutige Kategorisierung ähnlicher Herkunft dar.

Als zweites wird untersucht, ob Dokumente gemäß dem Stil der Urteilssprache zu zwei Generalanwälten (Juliane Kokott und Paolo Mengozzi) zugeordnet werden können. Wie bei der ersten Clusteranalyse liegt in diesem personenbezogenen Subkorpus ein homogenes kategorienkonformes Ergebnis vor.

Als letztes wird untersucht, wie die Urteile anhand von Themen wie beispielsweise Niederlassungsrecht, freier Dienstleistungsverkehr und Sozialversicherung miteinander verglichen werden können. Auffällig ist hier, dass die Ergebnisse deutlich heterogener ausfallen als in den anderen Fällen. Während kleinere Subcluster in Bezug auf Niederlassungsrecht und Sozialversicherung eindeutig zu erkennen sind, verteilt sich das Thema Dienstleistungsverkehr stärker.

Die drei vorgestellten Analysebeispiele zeigen die grundsätzliche Anwendbarkeit der Stilometrie auf juristischen Fachtexten und erste Hinweise für weitergehende Analysen und intellektuelle Vergleiche zwischen einzelnen Dokumenten.
Literatur:
Auer, A., Berteloot, P., Mielke, B., Schikora, C., Schmidt, T. & Wolff, C. (2019) Stilometrie in der Rechtslinguistik. In: IRIS – Proceedings of the 22nd International Legal Informatics Symposium (pp. 375-385). https://epub.uni-regensburg.de/43564
Schmidt, T., Bauer, M., Habler, F., Heuberger, H., Pilsl, F. & Wolff, C. (2020). Der Einsatz von Distant Reading auf einem Korpus deutschsprachiger Songtexte. In Book of Abstracts, DHd 2020 (pp. 296-299). Paderborn, Deutschland. https://epub.uni-regensburg.de/43704
Schmidt, T. & Kleindienst, N. (2020). Investigating the Transformation of Original Work by the Online Fan Fiction Community – A Case Study for Supernatural. Digital Practices. Reading, Writing and Evaluation on the Web. University of Basel, Switzerland. [Research Gate]
Schreibe einen Kommentar